Saving time and storage (with style)
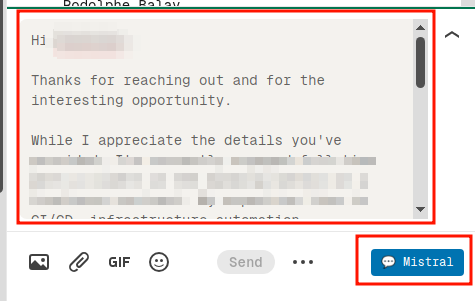
I reply to all recruiters for a long time. This became a chore over time, so I've developed a userscript that is loaded on every LinkedIn conversation, and calls Mistral AI to generate a reply in my preferred style. With every conversation I open, I hit this button and it will reply adequately, with respect to the history of the conversation, my priorities of the moment, the language of the conversation, the tone, etc.
It is then up to me to post the proposed answer as-is or to discard/edit the proposal
Dropbox storage optimization
As a parent, I developed the habit of archiving digital souvenirs of our kid’s life. Those pics and videos accumulate. As someone very organized, I like to avoid duplicates and also save the correct metadata (EXIF) in our pics and videos, which proves to be challenging with older pics from WhatsApp groups.
I wanted also to ensure that every time I get pictures and videos shared via WhatsApp family groups, I collect them in our Dropbox. This is done via Syncthing-Fork (Android client) and syncthing servers running on my Cloudron and my Macbook Pro. Syncthing monitors all folders that can contain videos or pictures. This helps effortlessly move all my pics/videos
- Moves all new pics/videos from Android-monitored folders to Dropbox. As those folders are kept in sync via Syncthing, if I move a pic/video out of the monitored Syncthing folder to Dropbox, it removes the pics/videos from all locations monitored by Syncthing on my Android, so it helps organizing things on Dropbox while also making room on my Android device. Syncthing is set up manually, but it’s easy to manage.
- Detect all pics/videos which do not contain a face, this is done using YOLOv5 by Ultralytics. The script was generated via LLM.
- Remove duplicates via some scripts (generated by LLM) or via https://github.com/arsenetar/dupeguru (manually, via UI).
- Compress/convert pictures and videos using https://ffmpeg.org/ which is installed locally, this achieves saving hundred GBs of data thus can reduce the bandwidth and resources needed for downloading, syncing, displaying such files. On top of this, I require less amount of storage, thus I can keep cheaper Dropbox subscription for longer. LLM generated most of the scripts needed for the task.
Newsletters summaries
As explained in a previous blog (https://morgan.zoemp.be/indieblog/), I'm keeping track of all new blog posts listed in https://indieblog.page/. I first cooked a daily RSS for it, using LLMs. This proved useful but as the list of RSS feeds grows over time, I came to realize I needed to better filter the list, or to limit the output. I don't want the filter to be too random, I want it to be based on my taste, so I created another RSS feed which is a LLM-aided summary of the first RSS feed.
Correcting or translating text
I asked an LLM to review this blog post. The instructions were simple: don't mess with my style, just flag the important fixes. I also asked for a permalink suggestion — one single English word, ideally fun or Gilfoyle-approved. The result is what you’re reading now. This very paragraph was, in fact, fully translated from a French original 🙂 .
What else?
I’ve shown a few cases where LLMs save me time or help improve my productivity. There are many more I haven’t covered, where I use LLMs to generate reusable scripts. Once a working solution is cooked, the LLM is out of the picture — most of the time. When a script needs to depend on AI to work, I mostly use Mistral: cheaper than OpenAI, and I don’t have to sacrifice my soul (or card) to use it. Automatic replies and content summaries are cases where interactive AI calls make sense. Still, I prefer to limit such usage — it makes my productivity overly dependent on fragile APIs and unpredictable outputs.