Seriously I wonder what is wrong with us, computer scientists and computer hobbyists. I thought I loved markdown, that I needed to keep telling the world about it, but what renders in Gitea is not rendering the same in GitHub, nor in Obsidian. I'm likely idiot, let's find out.
The guide at https://www.markdownguide.org/book/ already starts by confusing its readers, looking for simplicity, with prompting the user to pick between normal or extended syntax. The top menu also mentions hacks and tools and books. Woot ? Aren't we talking about a simple text format and about making things simpler ?
This can't be so complicated, at least I thought. Then I visited https://en.wikipedia.org/wiki/Markdown#Implementations and fallen of my chair -- note the >dramatic< tone here, but I'm only sitting in my sofa and avoiding sleep, I'm all fine.
Damn, even on Markdown supposed to provide a simple and better source format and publishing tool than HTML, we experts can't agree. Myriad of tools and implementations each extended by a few more artisanal tools here and there, millions of hours wasted ?
They are plenty static site generators and people crafting them and enriching markdown with details to hopefully generate, well, mostly valid HTML ? Or not ? Last time I checked, only an handful of those would take care of this goal.
We could chose to go back to working with text or HTML without tools in our way. This blog post for instance is almost just text and links, nothing much I require from markdown. This likely makes this portable. No transpiling needed, no tools.
It's NOT SO HARD and still readable. This blog post also has links that do not require remembering keyboard shortcuts on Mac for [Title](...) nor combining any special key.
Markdown is like sharing a recipe, but everyone reinvents a different complicated meal.
I'm addicted to Changedetection for spying on website changes and internet search results for specific keywords, Occasionally also for monitoring price changes. It's quite handy to discover new links added to web directories, or stay updated with some websites that do not provide any RSS feed.
Context
I'm watching hundred of URLs.
I often spy on webrings and blogrolls to discover new interesting links, and also on search engines results for specific keywords.
I'm self-hosting Changedetection through Cloudron.
I'm mostly following through those watches via my RSS Reader, Miniflux.
For some specific changes, like weather bad conditions, I subscribe via ntfy.
Anyway, I've developed a few habits that fit my workflow so well for every new watch, which are:
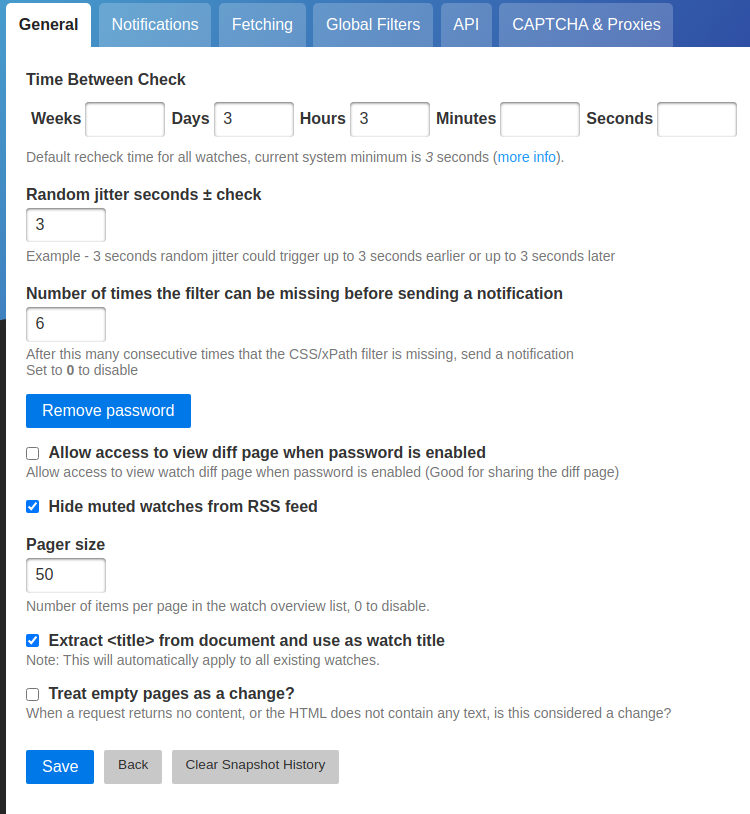
Settings > General
This is where we set defaults for all future watches, it's pretty obvious you must start here. Here is my current setting:
Time between check: By forcing a convenient interval between checks, you try to find a balance between information overload and staying current. Pick your poison, but don't hesitate to override this setting at per-watch level.
Extract from document and use as watch title: it's convenient to let Changedetection take care of naming your watches based on the webpage titles rather than leaving the sometimes very long and non human-friendly URL as a default description.
Random jitter: this is handy to avoid stressing your I/O too much.
General > Group tag
This one is mostly for better organizing stuff, as I mentioned I follow those changes through RSS, I noticed it was harder to distinct between important and less important stuff because I was following the default RSS feed, but Changedetection provides distinct RSS feeds per groups/tabs of watches, and that's my preferred workflow now.
I'm trying to always set a label, I have around 15 in total, some for specific interests (privacy, discovery aka list of links, devops, music, ...) or specific people, locations and business updates. The rest is generally less important and is labelled with things like FOMO, misc, ...
Those group tags appear as labels next to the URLs you are watching.
If you want to watch a whole group through RSS, link is at the bottom right of the page on the group tab.
Filters & Triggers > Remove elements
It's common on bloated rich web pages to want to focus on specific parts, like everything between <header> and <footer> sections, so I sometimes have to add footer and header. It's mostly needed for sites like eBay, 2ememain, where we can buy and sell things.
Filters & Triggers > default filter and triggers
This is purely for spam reduction as I mostly want to know when something new is made.
Sometimes I also enable Sort text alphabetically depending how the page is updated by its author.
🆕 Those new settings have been added recently and I'm also enabling them on new watches:
Extension
Try the web browser extension for Chromium based browsers, it makes watches one-click away.
Next
I've opened a discussion in Changedetection's repository to talk about how repetitive it feels to me, in the hope we can see something like template settings be proposed in the future, at least for the filters & triggers which I consider is not too hard to start with.
I deal with computers, hence I want things to work the most boring and reliable way possible, with automation, procedures, scripts, not through magic.
Hence, while I love tools such as Atuin, I've a problem with their slogan "Making your shell magical" and generally speaking with any product using such selling argument, especially AILLM-based products.
For this reason, I'm usually against any kind of black box and one-for-everything tools and platforms that want to ease our lives by hiding the complexities. I think that the only result we get out of those abstractions is complexity, pain, and a culture of incompetence and dependability. I mean, if you want to deal with technology, at least you should understand it.
In the end, it's not all magic [1][2], but it can feel magic for sure once we lack understanding. Magic feels shiny and appealing after all, its antonyms say it all.
At work, there exist an onboarding procedure targeted towards new developers in the team, and this procedure relies on scripts which were left untouched for way too long. The bad things : the procedure is broken but nobody dares to fix it, instead the old timers in the team share dirty hacks and workarounds with the newcomers.
Once you face such problem, the only solution is to address the root causes, not the symptoms. I choose to take a look at the procedure, run it again and again after each attempted improvement, cut it piece by piece, shred or rewrite what seems unreliable and suspicious.
Magic exists, but I’ve never seen any in software. Problems are logical. Nothing is impossible. You can solve this problem.1
As a software engineer, please don't fix symptoms. Don't get too used to deal with crap and unsolved problems. Don't be lazy, don't accept the status quo, make the hard work to understand and solve the problems. Set your focus on understanding things deeper. Enhance your and everyone's knowledge. Be a firefighter against ignorance, and help educate your peers to be better at understanding why things work or doesn't.
Sometimes, especially at night, I can't help but I feel the need to hunt down a topic and explore any link in my way til I reach an answer or a dead end.
Sometimes I publish those findings in Shaarli.
This time it was about researching a minimalist tool for blogging, something like bashblog or mkws.
It's not always a victory. Maybe next time. After a good rest.
This page is regularly updated. Feel free to use the scripts and take ownership of them. You can support me through Support of course :-)
I'm avid of content curation using RSS feeds. Let me share some of my tips here and some code. This is a living document so please come back for new tips 🙂 and explore my other articles on this topic.
Some of those tips rely on Userscripts which are snippets of code executed automatically on web pages, and usually it's very handy to customize your navigation. I'm using the Custom JavaScript block in Miniflux Settings. But some scripts won't work because of reliance on external resources, and in that case I'm using Tampermonkey for special cases that require loading external resources (think CSP & co).
Translate entries (EN->FR).
As a Belgian product, I speak French and English and can get ouf of trouble in Dutch as well. Yet even if I read mostly in English, I like from time to time to relax my brain and read in French which I speak natively.
My user scripts calls SimplyTranslate and thus clicking this button at the bottom of english articles...
Filter categories (remove empty ones) using Custom JavaScript block
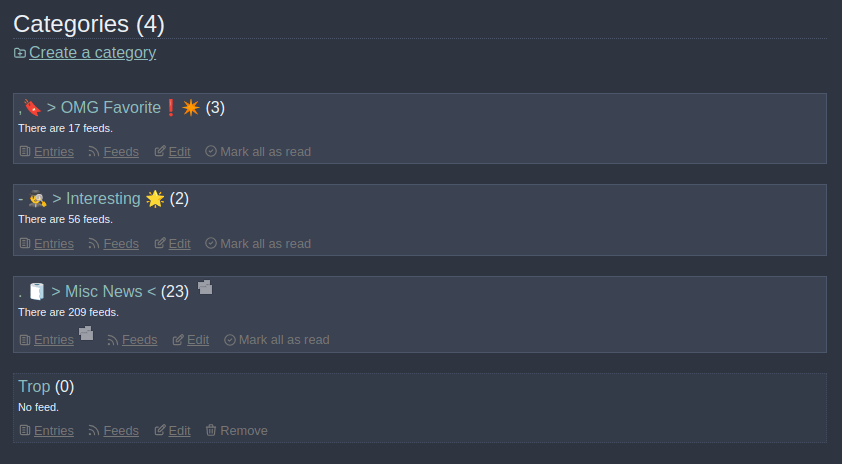
There is by default no distinction between categories with or without content, and it can be annoying. I made a user script to remove categories with no content to read.
Before applying the script, we have some categories, including one with (0) unread entries.
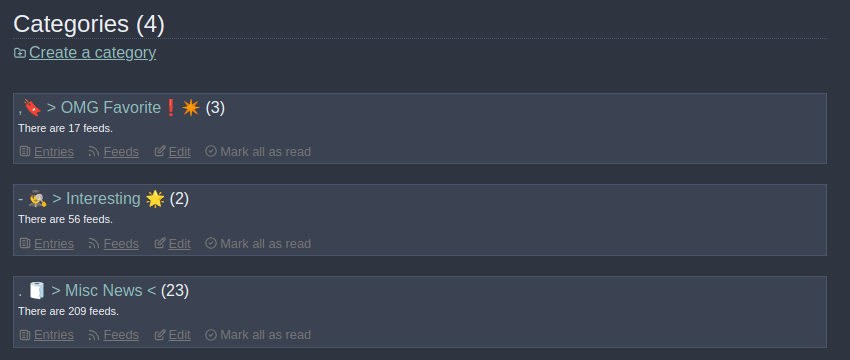
After
The category with (0) unread entries is hidden.
Feed organizer - using Tampermonkey
This one is for grouping together all feed entries by feed/author in the main on unread, read, and starred pages. I needed this one because by default, in unread tab, the feed entries are mixed all together and I often wanna consume content per feed/author and not in chronological order.
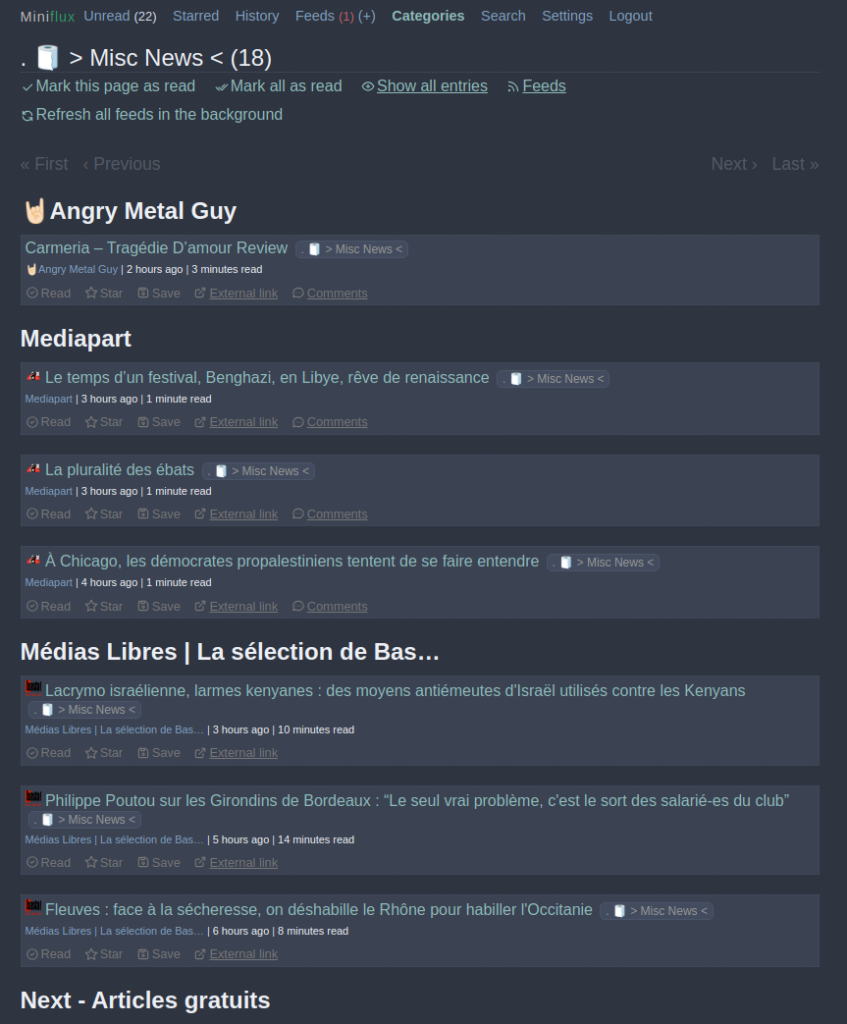
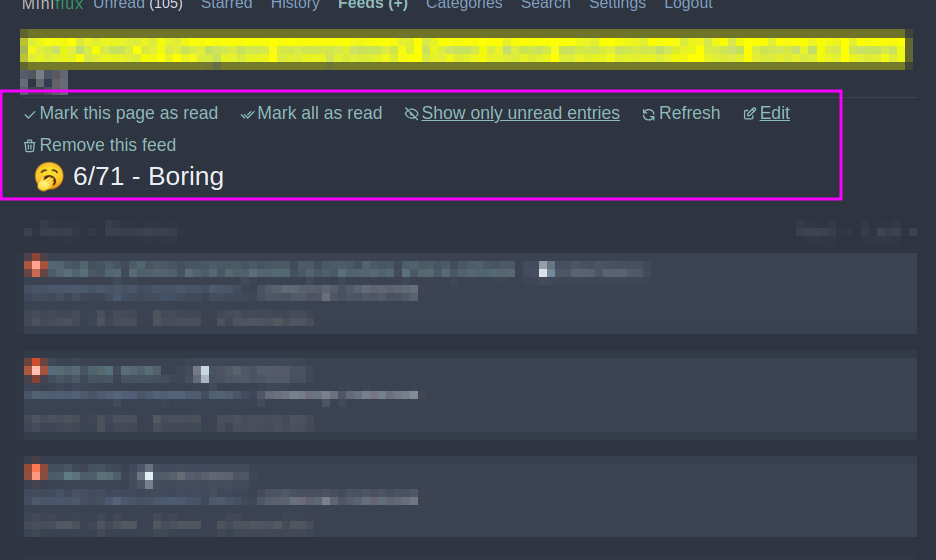
Distinct boring from interesting feeds thanks to objective ranking - with Custom JavaScript in global settings
When opening the "Show all entries" view of a feed, this trick will show you if you shall keep this feed or not. The classification is based on the ratio of starred entries vs total. In this case, clearly, my assistant tells me it's quite 🥱 boring. Other values are: Thinking 💭 (in case we lack data), Interesting 😍 (we star a lot of items), Thinking 🤔 (in case we stared at least some entries). Feel free to make it yours and customize the behavior!
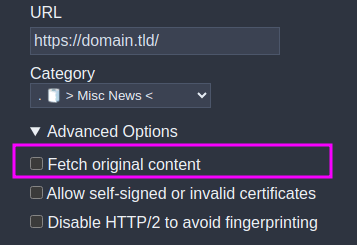
This is a trick that works well with the majority of feeds so you can fetch the whole article content in your reader instead of just the excerpt.
Filter feed entries by title / content
I've customize the feed settings to exclude specific keywords, and on top of this I've also global rules which apply to all feeds, for excluding feed entries when keywords are found in their content or title. This makes it easy to exclude clickbait uninteresting or depressing content 🙂
In this case I follow news with heavy metal album releases and I'm excluding specific genre like Death Metal. I'm also abusing the feature to avoid being spammed with recurrent news like Olympic games (Paris 2024). Finally there are already many reasons for me to be anxious, and I do not need more. The last rule saves me from the useless negative news. I keep fine tuning the list and I could improve this by including terms from public blacklists, like this.
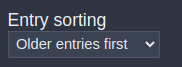
Entry sorting - Application settings
This is a setting that helps well to decrease the FOMO-scrolling, by ensuring the top of your unread list stays the same. So it is very simple, sort by Older entries first! Easy.
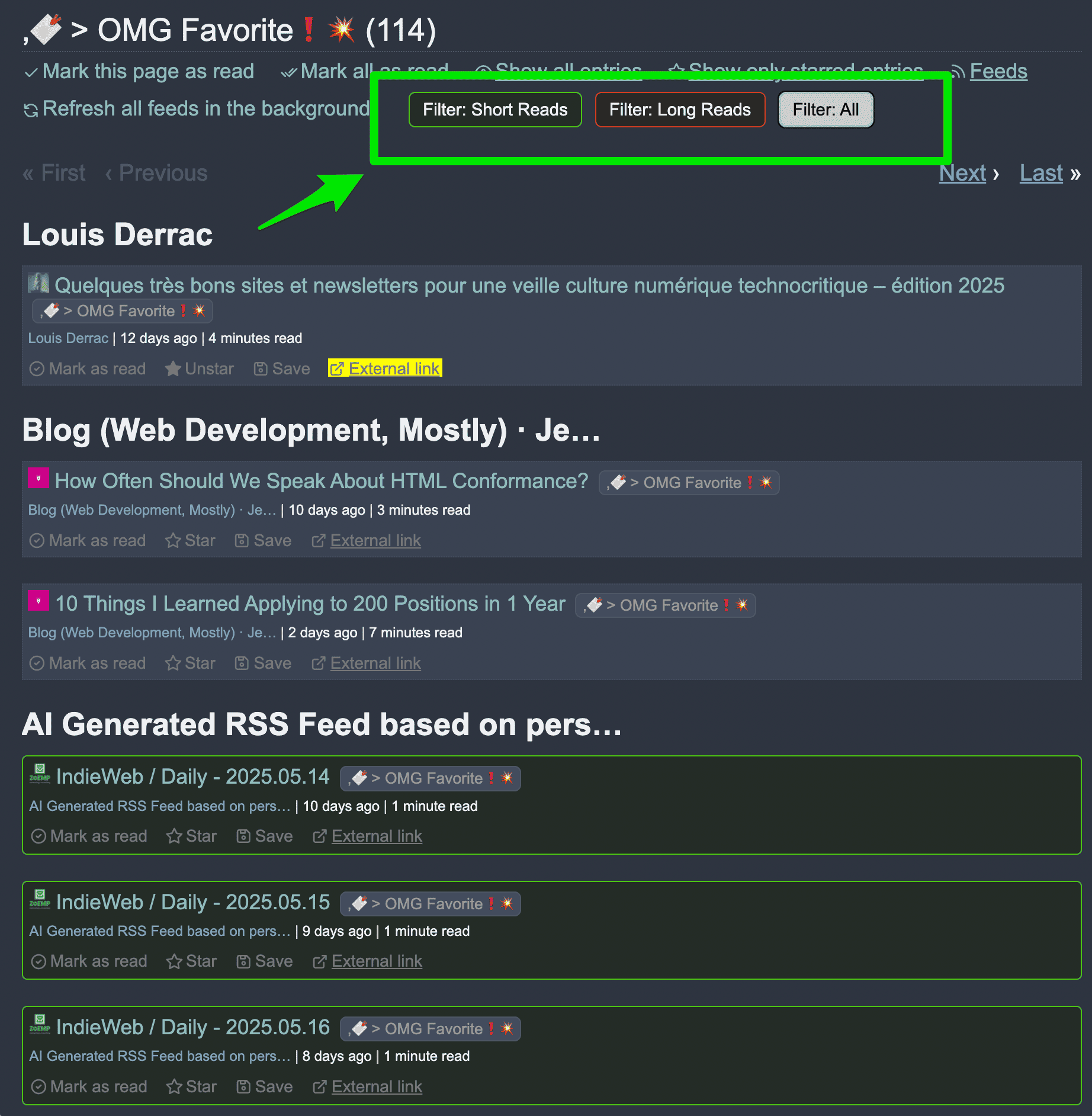
Filter short or long entries using Custom JavaScript rules
Sometimes I just have so much time and it is impossible to read long articles, so here is my life saver. This will hide all entries not matching the filter. I've added those filters on every page so I can focus on (e.g) short reads at the cost of 1 click only. Very practical when in a rush. The short entries will be highlighted in green. The long entries will be highlighted in red.